modeling CRDTs in Alloy - counters
Brian Hicks, November 27, 2023
Hey, welcome back! Last time, we introduced conflict-free replicated datatypes (CRDTs) and modeled them in Alloy by using boolean OR as our merge function.
As a quick recap, CRDTs give you eventual consistency, no matter how out of sync the data originally was. This makes them great for local-first or networked multiplayer applications. If you can write a merge function for a data structure that is commutative, associative, and idempotent, you might be able to build a CRDT on top of it.
Further, we're modeling all these semantics in Alloy, a lightweight formal methods tool good for modeling and analyzing data structures. We'll see some cool stuff it can do in a second.
Counting Birds
Last time our document was a single boolean. That's useful, but we can't build an application on top of it, so let's keep moving. To get much further, we're going to have to figure out how to sync numbers back and forth. Let's use the the Great Backyard Bird Count as an example. Say we're counting red-tailed hawks:
- Everyone starts at zero.
- Person A sees a hawk! Ka-kaw! They increment the counter by one.
- Person B sees another hawk! Screeee! They increment the counter by one, too.
- Person C sees two hawks. Wow! Of course, they increment the counter by two.
- Day's over; good job everyone! Sync up your apps and lets see how many hawks we saw total.
At first glance, we might want to use + as the merge function. But remember, that's not idempotent. So this might happen among three people:
- The group has seen four hawks total. Person A and person B have seen 1 each, person C has seen 2. Nobody has talked to anyone else.
- Person A and person B sync and set both their totals to
1 + 1 = 2 (one from each, the initial count) - Person A and person C sync and set both their totals to
2 + 2 = 4 (two from A because of the previous sync) - Person B and person C sync and set both their totals to
2 + 4 = 6 - Further syncs happen, and the result increases every time.
In other words, we can return with a huge number of hawks when really we only saw four. That's not what we wanted! This fails because + is not idempotent: adding any meaningful number will always change the result.
What if we used max instead? It's commutative, associative, and idempotent, but the semantics don't work out here: if we used max to merge, we'd only get to see the max of hawks that any one person had seen.
However, max would work if we synced one counter for each person and then added them together locally to get the result! Let's look at an example:
- Just like before, the group has seen four hawks total. Person A and person B have seen 1 each, person C has seen 2. Nobody has talked to anyone else.
- Person A and person B sync their totals, going from person A's
{a: 1} and person B's {b: 1} to {a: 1, b: 1}. - Person A and person C sync their totals, going from person A's
{a: 1, b: 1} and person C's {c: 2} to {a: 1, b: 2, c: 2}. - Person B and person C sync their totals, finishing the sync. Now everyone has
{a: 1, b: 1, c: 2} and anyone can compute that we've seen four hawks total.
When you have a conflicting value (say B saw another hawk later) you take the max of that person's count when syncing.
This also has the nice property of moving information through the system without requiring everyone to talk to everyone else. Consider what would happen if we did A+B, A+C, A+B instead of ending with B+C. We'd end up with the same value, since A+C would have given A the count to pass along to B, except that B and C never have to talk directly. It's eventually consistent!
Moving to Alloy
Let's model this scheme in Alloy. We'll model an ID to represent each individual birdwatcher:
sig ID {}
We'll also model a Document to allow each person to keep their count and the count of each of their peers:
sig Document {
id: one ID,
var counts: ID -> lone Natural,
}
A -> lone B means "each A maps to at most one B." In other words, it makes ID unique in counts for each Document (the way you'd expect a dictionary to work in an implementation.)
We have an error already, though. When I run this, Alloy gives me and edge case where we use the same ID for multiple documents:
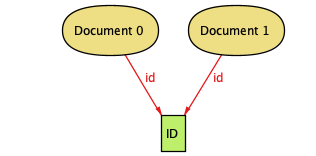
If this happened we'd lose data since we couldn't distinguish between values we needed to add and those we needed to max. Better disallow that in the model:
fact "no two documents can have the same ID" {
// "disj" means d1 and d2 can't be the same document
no disj d1, d2: Document | d1.id = d2.id
}
As always, adding a fact weakens our spec by making assumptions. So let's think: can we actually get rid of ID collisions when we implement this spec? Well, maybe… in real life, we'd use some ID scheme that we were reasonably sure would never collide. In production CRDTs, it seems like this means using UUIDs a lot of the time. Good enough for me; let's move on.
With this change, we can get some more interesting instances of the data structure. For example, here's what it could look like when these counts maps are filled out:
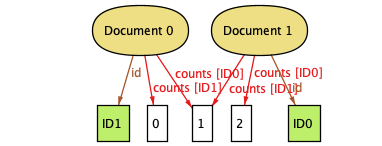
(You don't need to know how to read this example, but if you want to: the keys in the map are represented by the labels on the arrows. For example, "Document 0 has a count for ID 1 of 0".)
Merging
We don't have a way to sync yet, so let's start fixing that. Let's define merge, as well as adding checks that it satisfies our three laws:
fun merge[d1, d2: ID -> lone Natural]: (ID -> lone Natural) {
// intent: set each value in the document to the maximum value
// of that key in all the documents we're currently merging.
let allCounts = d1+d2 |
{ id: ID, count: Natural |
id->count in allCounts
and count = nat/max[allCounts[id]]
}
}
check MergeIsCommutative {
all d1, d2: Document |
merge[d1.counts, d2.counts] = merge[d2.counts, d1.counts]
}
check MergeIsAssociative {
all d1, d2, d3: Document |
merge[merge[d1.counts, d2.counts], d3.counts] = merge[d1.counts, merge[d2.counts, d3.counts]]
}
check MergeIsIdempotent {
all d1, d2: Document |
merge[d1.counts, d2.counts] = merge[merge[d1.counts, d2.counts], d2.counts]
}
Alloy says it can't find a counterexample for these three checks, so it looks like we might be in business.
Actions
Next let's set up some things our documents can do. First, we should be able to increment a number in a document by removing the old count for this document and ID and adding the new one:
pred increment[d: Document] {
let current = d.counts[d.id] {
counts' =
counts
- d->d.id->current
+ d->d.id->bounded_inc[current]
}
}
About all the arrows: a->b->c creates a three-valued relation (you can think of it like a 3-tuple if it helps: (a, b, c).) Since counts is actually a mapping of document-to-id-to-natural, we need this level of precision. However, this is the only place we'll this since writing d.counts will pop the Document off the left-hand side of the relation, leaving us with ID -> Natural (as in our sig.)
I had to write a bounded_inc helper function to write increment. Here it is:
fun bounded_inc[n: Natural]: Natural {
n = nat/last implies nat/last else nat/inc[n]
}
This was necessary because Alloy's numbers are actually just regular sigs with an ordering.
Since we only deal with a bounded number of instances for each sig, addition and counting has a gotcha. Say you only knew the numbers 1 and 2: counting works fine up to a certain point, but if someone asked you "ok, and what's after two?" you wouldn't know. This is exactly what's going on with Alloy, which will return a blank set if you run out of numbers. Specs can define semantics specific to their applications, though, and in ours I've decided that incrementing past the max is simply not allowed—a number will just stop growing a certain point.
This should not really affect the soundness of our spec, but choosing limits like this requires careful thought. Alloy is not designed for numerical computing, and forcing it means dealing with weird edge cases like this. Fortunately, that's the only place in the spec we should have to deal with this.
Now We Can Sync!
Let's move on to sync, which should merge two documents:
pred sync[d1, d2: Document] {
let merged = merge[d1.counts, d2.counts] |
counts' = counts ++ (d1->merged + d2->merged)
}
Next the little bit of boilerplate that we need to treat these as actions:
pred init {
// intent: set every document to 0 for its own ID
counts = { d: Document, i: ID, count: Zero | d.id = id }
}
fact traces {
init
always {
(some d: Document | increment[d])
or (some d1, d2: Document | sync[d1, d2])
}
}
Finally, let's check idempotence like last time:
check SyncIsIdempotent {
always all d1, d2: Document |
(sync[d1, d2]; sync[d1, d2]) implies counts' = counts''
}
Alloy can't find a counterexample for this, so I think we're done! These documents should work as CRDTs! In fact, our counters here model something called a "GCounter" (a "grow-only" counter.) There are plenty of implementations out there if you want search for that term and find some real code to read!
But… GCounters can only count up. That's a problem, right? You might think "ah, we can get around that—each node could set its own count to whatever it wanted!" But we'd hit problems there on the first sync: since our merge function uses max, any time a node's counter decremented it'd go back up to the highest-seen value on the next sync.
There's a nice way out of this predicament, though: use two counters per document, positive and negative. Both counters always go up (so max doesn't give us trouble) and when you need to get the value out of the document, you sum up all the values of both counters, then get the final value from positive - negative. Ta-da! The final can now go up and down, and you have something called a "PNCounter" (a "positive/negative" counter.)
You might also look at this and think "yikes, that looks like a lot of memory for a single number… that would just be a single integer if this wasn't distributed." Yep! There's always going to be some overhead for syncing. You can minimize it, though, and people who make production-class CRDTs (like Ink and Switch) clearly think about data compression a lot! In fact, Jake Lazaroff has written an excellent blog post about doing this in an image-based CRDT. Go read that next!
Thanks to Alcino Cunha on the Alloy forums for helping me understand how set comprehensions could be used for merge, as well as pointing out that it should be possible to specify our checks with only events. Thanks also to Jake Lazaroff for reviewing an early draft and suggesting better ways to structure this.