Modeling Git Internals in Alloy, Part 1: Blobs and Trees
Brian Hicks, April 3, 2023
Today we're going to learn some Alloy by modeling Git objects.
What's Alloy?
I wrote this post for people who are meeting Alloy for the first time. If that's you, here's a quick intro: Alloy is a piece of software (with its own domain-specific programming language) used for making and checking models of other software. You use it to do "lightweight formal methods", focusing on approachable language and practical applications over full specification and formal proofs.
Alloy helps you think through problems by showing you both what's possible and implied in the models you give it. It can model whatever you care to express in its language, although some things lend themselves to modeling better than others. Some things I've had good luck with: data structures, database schemas, and UI states.
Alloy can exhaustively check conditions in models under a certain size. This gives us a tradeoff: you don't get a full proof that your condition holds (although you can get close enough for most purposes) but it can execute your specs much faster than other tools in the formal methods space. This is almost always fine. Just be cautious about saying things like "I proved this using Alloy"—it's not that kind of tool.
You can download Alloy at alloytools.org. If you're interested in learning more after reading this, I've also written modeling database tables in Alloy as well as a few other posts.
Git's Internals
Now, to Git. Git stores all the code and commits in your repo in a content-addressable store. That means that if you know the hash of something, you can retrieve it from the store. This allows Git to do cool things like syncing and deduplication, but it's also the source of some of the weirder parts of Git's behavior from a beginner's perspective. Once I learned about the internals, I found it a lot easier to reason about what it was doing. If you're learning about them for the first time now, I hope you have a similar experience!
I based these models off of the Git Internals - Git Objects chapter of the Git book. I won't go into nearly as much detail about how Git works as they do there; this post will be more about modeling. If learning both the modeling tool and the domain at once is too much, go read that chapter and come back.
Blobs
Let's look at blobs (used for basic content storage) first. We can tell git to create one like so:
$ echo 'Hello, blob!' | git hash-object -w --stdin
9b4b40c2bca67e781930105fa190b9b90235cfe5
Git gives us a hash of the content on stdout. To retrieve it again, we just ask:
$ git cat-file -p 9b4b40c2bca67e781930105fa190b9b90235cfe5
Hello, blob!
Like I mentioned above, these blob objects are content-addressed. In practice, that means they can't be duplicated. If you run the command to store Hello, blob! twice, Git will give you the hash again but not change anything on disk (since the blob is already stored.) We can get a new blob, along with a new hash, by changing the content:
$ echo 'Hello, Alloy!' | git hash-object -w --stdin
39528abd81b13b2731d47f86206351a61f1e6484
(Git produces these hashes consistently across different installations, by the way. Try running them in some repo on your computer. You should get the same hashes!)
Since this is basically the same behavior as sets, we can model the whole thing in Alloy like so:
sig Blob {}
This introduces a sig, our basic unit of modeling. I find it easiest to think of sigs as sets: we can have zero Blobs, or one, or many, but never more than one of the same Blob in the set.
We can ask Alloy to execute this model, giving us examples of Blob. If we do so, then click "Show", it gives us a window like this:
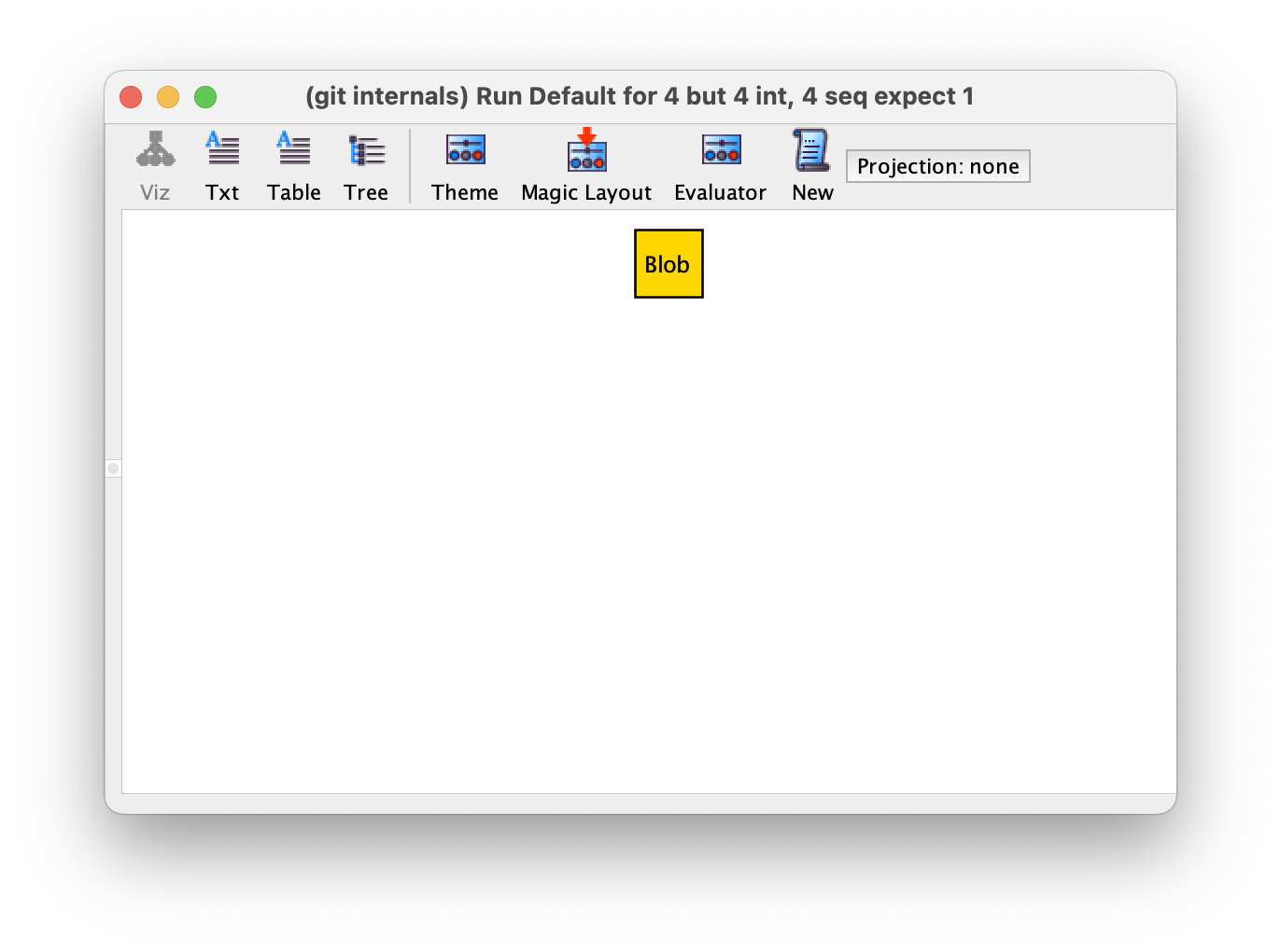
You can click "New" a bunch of times here. Alloy will start off with no blobs, then show one, then two, three, and four. At four, if you click "New" again Alloy will tell you that "There are no more satisfying instances."
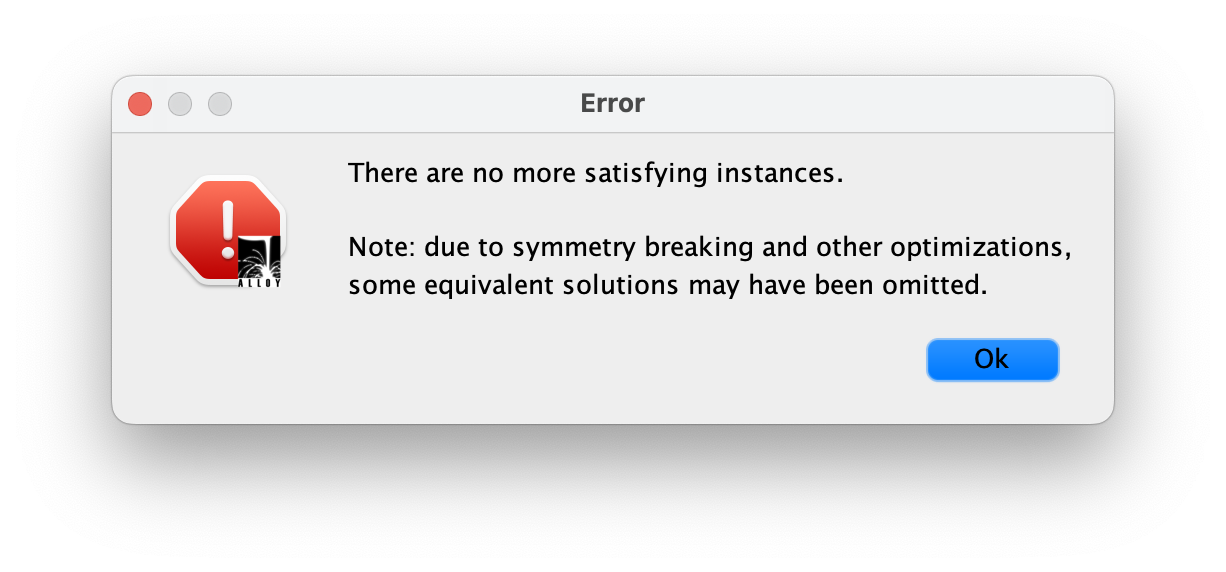
This means that we've seen all the possible ways for there to be blobs under the current configuration. Alloy limits us to four of each sig by default. We can raise this if we need, but in my experience Alloy can find most interesting things under this limit.
At any rate, no matter how many blobs we have, we still haven't modeled enough to show useful things about Git. Next up in the Git book: trees!
Trees
Trees work basically like directories in a filesystem hierarchy. Their hash is based on the hash of all the content they contain, plus the filenames of that content. We can create one by associating blobs with filenames in the index (kinda like git add foo.txt but with the object hash instead of reading from the project source.) It looks like this:
$ git update-index --add --cacheinfo 100644 \
9b4b40c2bca67e781930105fa190b9b90235cfe5 hello-blob.txt
$ git update-index --add --cacheinfo 100644 \
39528abd81b13b2731d47f86206351a61f1e6484 hello-alloy.txt
$ git write-tree
3ee29075f260c5eebd8b9480b6464a7612668dde
This gives us a tree object containing the hashes we wrote before. We might try and model trees like this in Alloy:
sig Tree {
children: set Blob,
}
But that won't work: trees can also contain trees! We can demonstrate using git read-tree (it works like update-index --add, but puts the content of the tree under the given prefix.)
$ git reset --hard # to clear out the staged files
$ git read-tree --prefix=greetings 3ee29075f260c5eebd8b9480b6464a7612668dde
$ git write-tree
a0776403e71047444987c67405757a1dbeb0f263
$ git cat-file -p a0776403e71047444987c67405757a1dbeb0f263
040000 tree 3ee29075f260c5eebd8b9480b6464a7612668dde greetings
We need to change our modeling to allow for this. Luckily for us, it turns out that both blobs and trees belong to the category of "Git objects." Alloy makes this easy to model:
abstract sig Object {}
sig Blob extends Object {}
sig Tree extends Object {
children: set Object
}
A sig being abstract means that there aren't ever going to be any things that are only Object, but that Object can serve as a superset for anything extending it (you can think of it like an abstract class in an object-oriented language.)
Blob and Tree are now defined as extending Object. This means that they are non-overlapping subsets of Object. In other words, nothing is both a Blob and a Tree.
Finally, we give Tree some children. Defining it with set means that we could have zero, one, or many children (which is possible in git; I checked on an empty repo.) If we want one or more, we could say some. There's also one (which is what it sounds like) and lone (which is zero or one exactly.) These are all called "multiplicity operators." You don't have to specify one, although I always do because I forget what the default is and it's nicer to be explicit anyway.
Let's execute this model and have a look at some of the instances. For example, we can get totally normal-looking trees which contain other trees and blobs:

However, we've accidentally allowed some other stuff like…
Recursion! (dun dun dunnnnn)
Our current model allows the data structures we want, but it also allows stuff that doesn't make sense in Git. For example, trees can contain themselves, and contain the trees that contain them. Here's an example with all that happening at once:
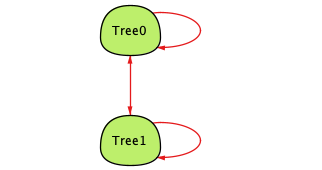
This shouldn't be possible, theoretically. Remember that this is a content-addressed storage system, so you need to know something's hash to refer to it. That means for something to refer to itself, you'd have to know the hash in advance, and the hash of the thing you create would change depending on that hash. Since hash algorithms aren't perfect, you can get two values that produce the same hash (a collision) but you'd have to get really lucky (or unlucky, depending on your perspective.)
I was curious about whether this was actually even possible or if Git would reject it, so I did some digging. Someone on Reddit had the same question and changed the source code to be dramatically more likely to have a collision (by changing the code to only use the first byte of the SHA-1 hash.) They got a segfault, which tells me that this isn't something that the Git authors designed for.
We'll use a fact to disallow this case. When we declare something as fact, Alloy will not allow any instances which would make the fact false. We should use these carefully—as in other kinds of reasoning, more axioms mean making a weaker argument (even though it's hard to not use any at all.)
fact "trees cannot refer to themselves" {
no t: Tree | t in t.^children
}
The ^ operator is new to us—it follows the "children" relationship one or more times. That means that we're saying "there is no Tree that is it's own child, or that child's child, or that child's child's child, and so on."
Once we do this, Alloy cannot find any more instances where trees refer to themselves, but it can still find plenty where trees contain other trees or blobs. Success!
We can, however, still get two trees pointing to the same blob. If we assume that these two trees are using the same filename for the blob, this shouldn't be possible, because they'd have the same hash.
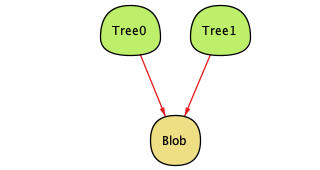
So we find ourselves at another fork in the road: we could either model naming files within trees or not. Like last time, you can make a convincing argument either way:
- If we add names, we'll be sticking closer to the way the actual system works. Trees exist as the equivalent of a directory in a filesystem, so it's a little weird to ignore names totally.
- If we don't add names, we'll keep the model simpler. However, we can assume that any time we see two trees with the same contents, at least child has a different name. Since a directory entry is a string, and there are effectively an infinite amount of strings, this seems like a safe assumption.
Again, I have to ask what we're modeling. If, right now, we were modeling the way that git checkout turns a tree into files and directories in the filesystem, we might want to add names. But since we're trying to understand Git's internal structure, it probably makes sense to leave them out (it makes our fact above much nicer, for one.) I usually add a comment documenting this, though, and I will in our final model.
That's all… for now
Today we've learned: how to make a sig, how to connect two sigs together, and how to force Alloy to disallow certain cases. We've also (maybe) learned a little bit about blobs and trees. The full, final model is below:
abstract sig Object {}
sig Blob extends Object {}
sig Tree extends Object {
// We're not modeling the mapping from name to object
// for simplicity's sake. If you see two trees with the
// same children, assume it's fine because the children
// have different file names.
children: set Object
}
fact "trees cannot refer to themselves" {
no t: Tree | t in t.^children
}
Over the next couple of posts, we'll build on this by:
- adding more Git object! Commits, references, and tags.
- modeling how commands like
git hash-object -w, git update-index, and git write-tree modify the object database to verify that statements like "trees can't refer to themselves" are actually true given the operations we can run. - modeling how everyday Git commands (the "porcelain"; things like
git add and git commit) map onto these lower-level operations. - and, if we're very lucky, we can model how
git syncs this all around when you run git push or git pull.
Stay tuned! If you'd like to be notified when I publish any of those posts, you can subscribe below.